Chatbot
This guide explains how to deploy DeepSeek-R1 large language model locally on NVIDIA Jetson Orin devices using Ollama (lightweight inference engine) for offline AI interactions with simple installation.
1. Overview
LLMs like DeepSeek-R1 are becoming core to edge AI applications. Benefits of running directly on Jetson Orin:
- Fully offline operation
- Low-latency responses
- Enhanced data privacy
Guide covers:
- Environment setup
- Ollama installation
- Running DeepSeek-R1 model
- Optional Open WebUI for web interface
[Image]Illustration: Web chat interface based on Open WebUI (placeholder)
2. Environment Setup
Hardware
| Component | Requirement |
|---|---|
| Device | Jetson Orin (Nano/NX/AGX) |
| RAM | ≥8GB (more for larger models) |
| Storage | ≥10GB (varies by model size) |
| GPU | NVIDIA GPU with CUDA support |
Software
- Ubuntu 20.04/22.04 (JetPack 5.1.1+ recommended)
- NVIDIA CUDA toolkit and drivers (pre-installed in JetPack)
- Docker (optional for containerized deployment)
⚙️ Use
jetson_clocksand checknvpmodelto enable max performance mode for best inference.
3. Install Ollama (Inference Engine)
Method A: Native Script Installation
curl -fsSL https://ollama.com/install.sh | sh
- Installs Ollama service and CLI
- Automatically handles dependencies
Method B: Docker Deployment
sudo docker run --runtime=nvidia --rm --network=host \
-v ~/ollama:/ollama \
-e OLLAMA_MODELS=/ollama \
dustynv/ollama:r36.4.0
🧩 Docker version maintained by NVIDIA community (dustynv), optimized for Jetson
Verify Ollama Running
ss -tuln | grep 11434
Expected output:
LISTEN 0 128 127.0.0.1:11434 ...
Port 11434 listening indicates Ollama service is running.
4. Run DeepSeek-R1 Model
Launch Model
Run 1.5B parameter version:
ollama run deepseek-r1:1.5b
- Ollama auto-downloads model if not cached
- Starts interactive chat in terminal
💡 Replace
1.5bwith8b,14betc. based on hardware capability
Model Version Comparison
| Version | RAM Needed | Notes |
|---|---|---|
| 1.5B | ~6-8GB | For Orin Nano/NX |
| 8B+ | ≥16GB | Requires AGX Orin |
| 70B | 🚫 | Not supported |
5. Web Interface (Open WebUI)
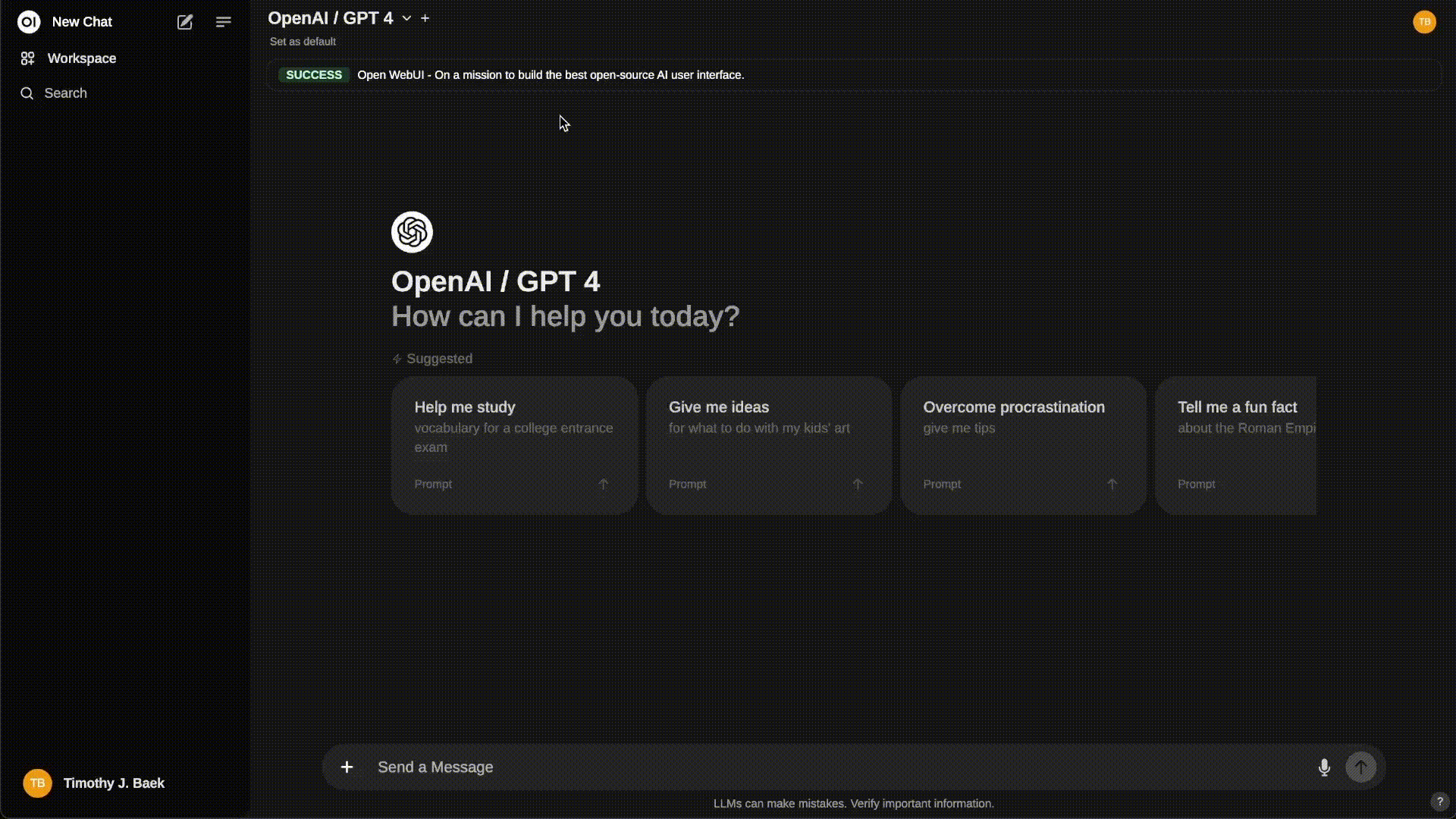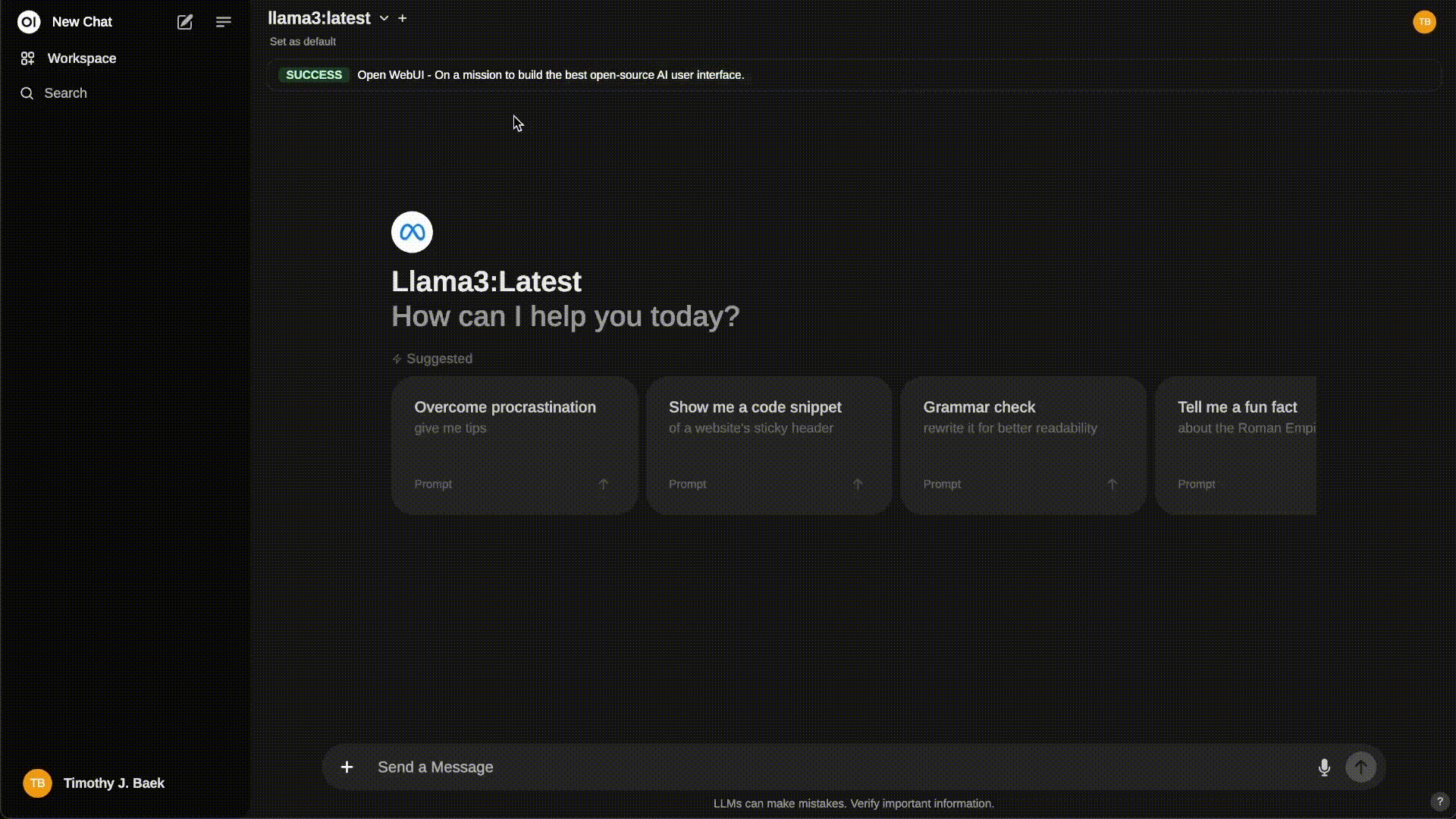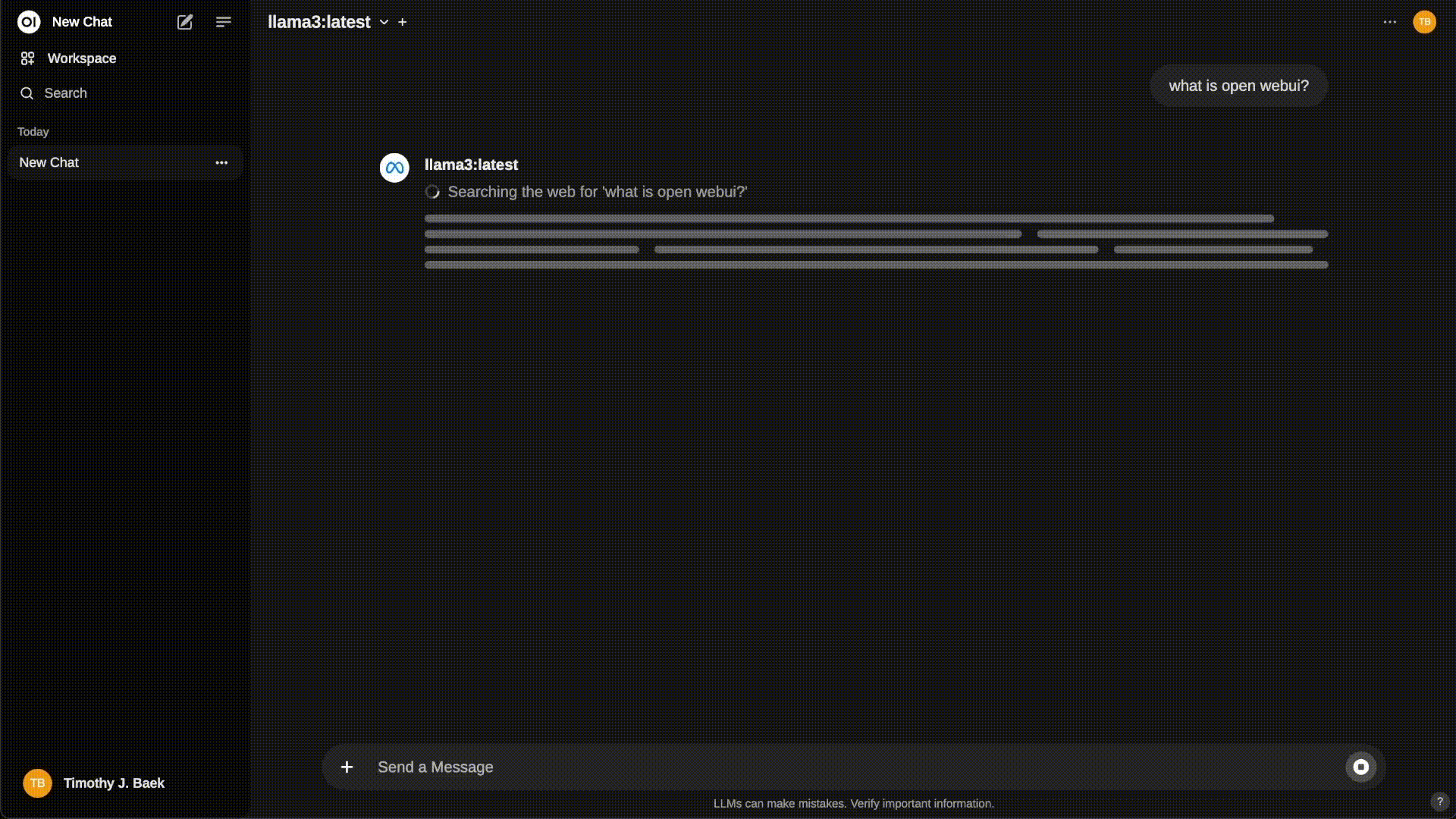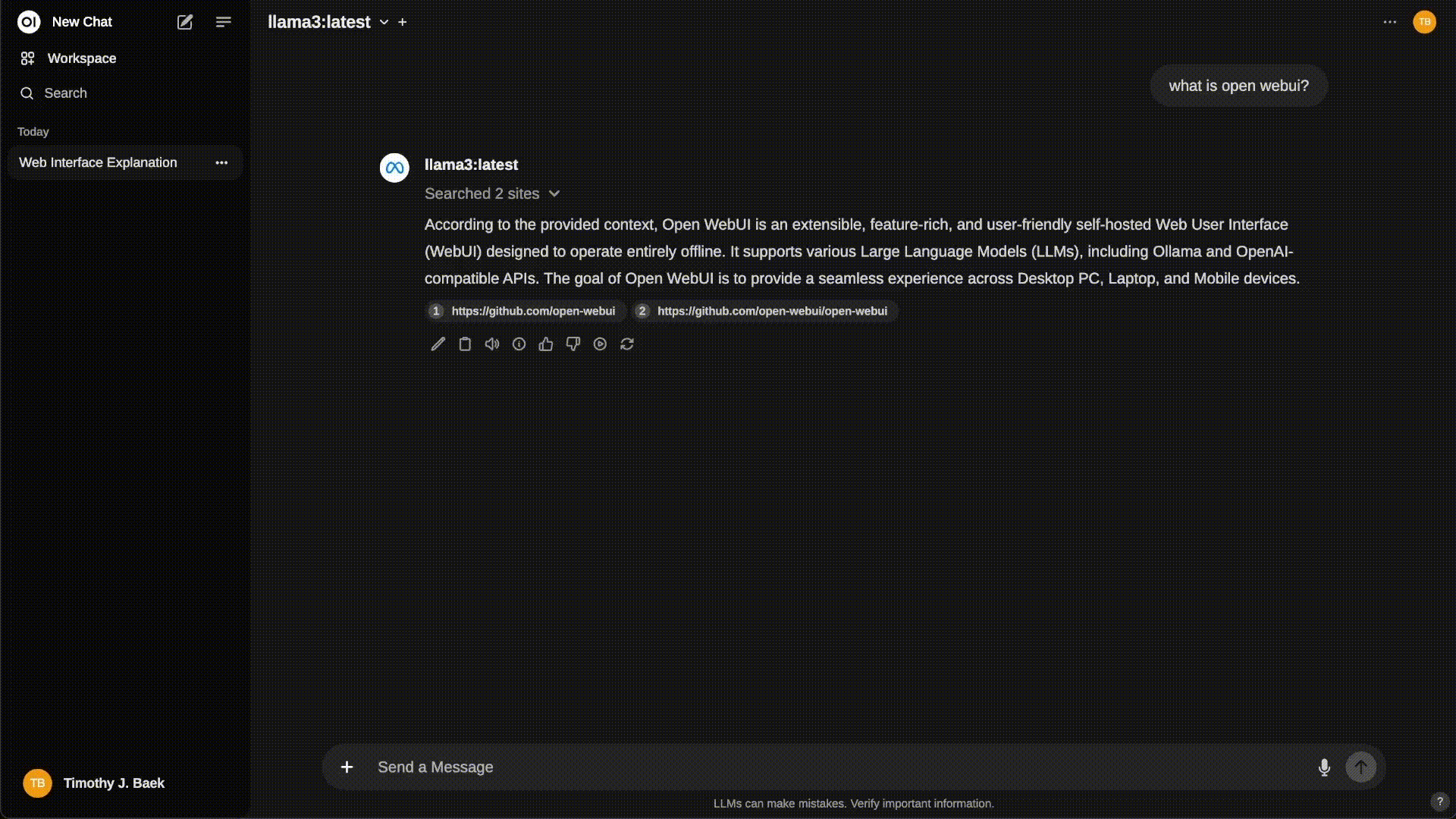
Open WebUI provides browser-based chat interface.
Install Open WebUI (Docker)
sudo docker run -d --network=host \
-v ${HOME}/open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Access WebUI
Browser access:
http://localhost:3000/
- Graphical interaction with DeepSeek-R1
- View chat history and responses
6. Performance Optimization
| Optimization | Recommendation |
|---|---|
| Memory | Use smaller models or enable swap |
| Jetson Mode | Enable MAXN + jetson_clocks |
| Model Cache | Ensure ~/ollama has space |
| Monitoring | Use htop, tegrastats |
📉 First model load takes ~30-60 sec, faster with cache.
7. Troubleshooting
| Issue | Solution |
|---|---|
| Port 11434 not listening | Restart Ollama or check Docker |
| Model load failure | Insufficient RAM, try smaller version |
| Can't access Web UI | Check Docker running and network |
| Ollama command not found | Reinstall or add to $PATH |
8. Appendix
Example Directory Structure
~/ollama/ # Model cache
~/open-webui/ # WebUI persistent data